In today’s data-driven world, intelligent, seamless solutions for data processing were never felt as urgently needed as it is now. Businesses do need instruments which can further facilitate the process of data aggregation and querying seamlessly by integrating with multiple sources of data. Enter QueryOptima: powerful middleware with the potential to change the game in the handling of data emanating from SQL, REST, and GraphQL APIs with an integrated approach superior to even canonical solutions like Cube.
Learn how QueryOptima beats the standard in terms of data optimization and BI integration, and how it will become the go-to for any modern enterprise out there.
Why QueryOptima is a Game-Changer
At the heart of QueryOptima’s attractiveness lies an unparalleled ability to connect diverse sources to your BI, which makes working with the ingestion and querying of data much easier. Now, imagine all having SQL databases, REST APIs, and GraphQL APIs right at your doorstep, amplified by fast performance, seamlessly integrated with your favorite BI tools: Apache Superset, Tableau, or Power BI.
What Sets QueryOptima Apart?
1. Unmatched Data Source Integration
The ease with which QueryOptima integrates a host of sources that include SQL, REST, and GraphQL APIs to unify diverse data into one actionable platform is unprecedented.
2. Lightning-Fast Performance with Apache Arrow
Sourced by Apache Arrow for in-memory processing, QueryOptima ensures that the most complex source ingestion queries are dealt with with remarkably minimal latency and offers high-performance analytics in record time.
3. Advanced Caching for Faster Results
Leverage advanced caching systems, such as Redis and Parquet, to reduce query execution time; thus enabling super-fast ingestions even when you work with enormously big data sources.
4. Version Control & Data Lineage
QueryOptima takes the notion of transparency to a whole new level since it enables Data Version Control and Tracking of Sources. You are able to track every modification you want and, of course, have full possession of your data for auditing purposes or to meet compliance regulations.
5. Big Data Scalability
QueryOptima is designed to scale easily in environments such as Kubernetes with high availability and fault tolerance, irrespective of data volume and query complexity.
How QueryOptima compares to Cube ?
| Feature | Cube | QueryOptima |
|---|---|---|
| SQL databases Source Integration | ✅ | ✅ |
| REST APIs Source Integration | ❌ | ✅ |
| GraphQL Source Integration | ❌ | ✅ |
| Semantic Layer | ✅ | ✅ |
| Built-in Caching | ✅ | ✅ |
| Version Control | ❌ | ✅ |
| Data Lineage/Source Tracking | ❌ | ✅ |
| BI Tool Support | ✅ | ✅ Superset, Tableau, Power BI, etc |
| Scalability | ✅ Horizontal scaling | ✅ Multi-node, Kubernetes support |
| Open-Source | ✅ | ✅ |
| Exposes APIs | ✅ SQL, REST APIs, GraphQL | ✅ SQL |
The Innovative Architecture Behind QueryOptima
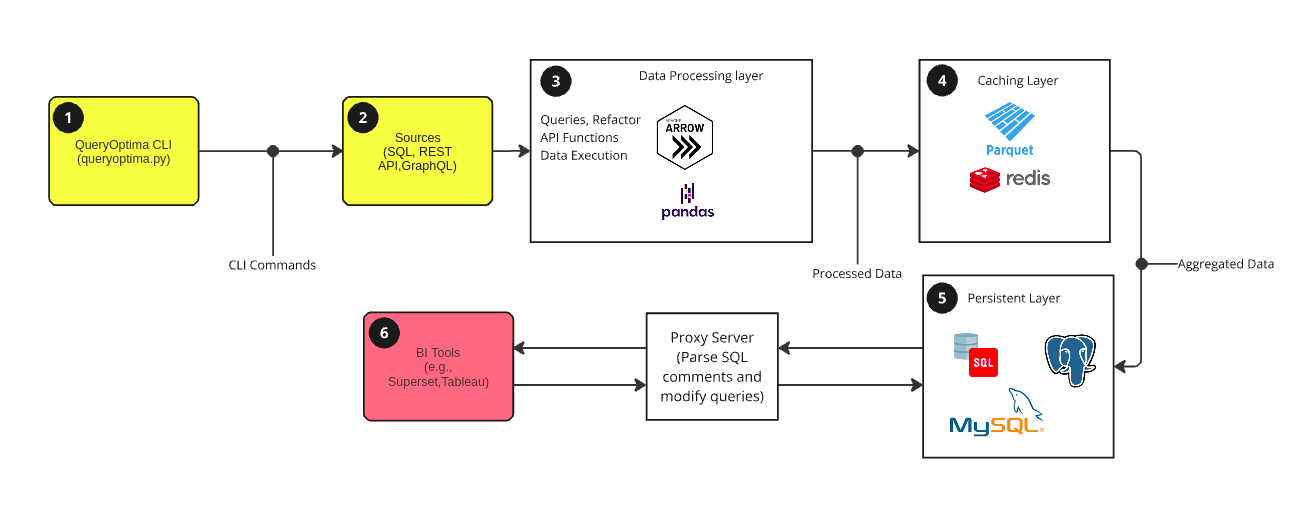
At its core, QueryOptima is built for flexibility, speed, and scalability. The architecture allows an intuitive queryoptima CLI interface that makes it easy for users to connect data sources, control caching, and run queries, offering a seamless experience. Then the Data Sources component integrates smoothly with SQL databases, REST APIs, and GraphQL APIs, making it ideal for businesses that rely on multiple data sources.
Following are three core components of this architecture:
Data Processing Layer
Powered by Apache Arrow and Pandas, this layer processes complex queries efficiently, ensuring fast data aggregation, joining, and storage.
Caching Layer
With support for Redis and Parquet, the caching layer speeds up query responses, especially for data that is accessed frequently.
Persistent Layer
Processed data is stored in reliable databases like PostgreSQL and Hive, which enhances performance for large-scale data processing.
This modular architecture empowers businesses to fine-tune their data operations, enabling them to gain insights more quickly and at scale—making QueryOptima a must-have tool for any modern data infrastructure.
Real-World Applications of QueryOptima
Thanks to its versatile feature set, QueryOptima can be applied to a variety of business needs:
- Fast Data Dashboards: QueryOptima’s cross-source querying helps data analysts create dashboards that pull data from SQL, REST, and GraphQL sources, providing real-time insights at a glance.
- Audit & Compliance: Industries like finance and healthcare, which require strict data auditing and traceability, can use QueryOptima to maintain detailed data lineage and ensure compliance.
- Data Aggregation Across Sources: Businesses can easily merge data from multiple platforms, such as combining sales data from SQL with customer data from REST APIs, for more comprehensive reporting.
- BI Reporting: By pre-processing data, QueryOptima helps BI tools deliver faster, more responsive dashboards and reports, enhancing decision-making for teams.
Conclusion: QueryOptima is the Future of Data Optimization
QueryOptima is much more than just a data optimization tool—it’s a game-changer for how organizations manage, process, and visualize their data. With seamless integration of SQL, REST, and GraphQL APIs, fast analytics, and improved transparency through version control and source tracking, QueryOptima addresses the key challenges businesses face with data today.
Boost your data operations with QueryOptima to achieve faster, more actionable insights.
Want to learn more? Visit the QueryOptima GitLab repository to get started!